xefer
URIs and Ids
· Friday, January 31st, 2003 ·

My original proposal for dealing with the problem of generating more palatable URIs
for accessing XBEL-encoded hierarchical data was to base the URIs on the “id”
attribute. This would be better than basing them solely on the <title>
elements of the resource and its parent folders since those titles can be lengthy and contain
spaces, etc. However, after thinking this approach through, I realize that because the id must be
unique across the entire document, it would be far too restrictive.
I’ve decided instead to key off of an element from the
Dublin Core Metadata Initiative, the refinement element
<alternative>.
The formal definition of this element is as follows:
Any form of the title used as a substitute or alternative to the formal title of the resource.
While this demands an extension to the standard XBEL schema, the element is one with standardized semantics; it’s better than the alternative of attempting to define a completely new element.
This element is similar in affect to the little known “SHORTCUTURL” attribute defined by the Mozilla project. This attribute is used to associate a keyword with a bookmark in the Mozilla browser. The name of the attribute is somewhat misleading as it really is simply a keyword, not a URL as defined by RFC2396. The name seems to derive from the fact that once a keyword is associated with a bookmark, typing the keyword into Mozilla’s URL address bar will dereference the bookmark URL.
The use of the <alternative> element will demand the declaration of a
namespace definition in the root XBEL element:
<xbel xmlns:dcterms="http://purl.org/dc/terms/">
<title>Standards Documents</title>
<info>
<metadata owner="Jeffrey Winter">
</info>
<description>
A collection of standards information
</description>
<folder>
<dcterms:alternative>xml</dcterms:alternative>
<title>XML Standards</title>
<bookmark>
<dcterms:alternative>xpointer</dcterms:alternative>
<title>XML Pointer Language</title>
</bookmark>
</folder>
</xbel>
The inclusion of the <dcterms:alternative> elements allow the bookmark above to be referenced as:
http://www.xefer.com/xbel/xml/xpointer
as opposed to:
http://www.xefer.com/xbel/XML%20Standards/XML%20Pointer%20Language
Additional constraints would have to be applied to the alternative value:
- It will have to be unique within its parent folder; i.e., none of the element’s siblings can have the same attribute value.
- The name cannot contain any “/” or “\” characters. This would disrupt the URI mapping scheme.
-
Only a single
<dcterms:alternative>element will be allowed for a<bookmark>or<folder>element.
In the absence of an <alternative> element,
the <title> will be used to locate the XBEL resource.
The OPTIONS Method
· Thursday, January 23rd, 2003 ·
After engaging in a discussion over on rest-discuss about how to best associate metadata with a web service, I've decided to use the OPTIONS method.
The OPTIONS method represents a request for information about the communication options available on the request/response chain identified by the Request-URI. This method allows the client to determine the options and/or requirements associated with a resource, or the capabilities of a server, without implying a resource action or initiating a resource retrieval.
This provides a way of binding a resource with it’s metadata in a way that doesn’t require any extensions to HTTP. I’ve seen one alternative method proposed, but it does involve the use of extension headers. If some standard convention ultimately emerges, I’ll move to that.
One concern that was raised was that RFC2616 states that the OPTIONS method is not cacheable; the concern being that it would be essentially impossible to know how long the OPTIONS response would be valid. Roy Fielding posted a clarification stating that this is just the default; cache-control can be employed, allowing the server to define how long the metadata is guaranteed to remain valid.
For any resource, the response to an OPTIONS request will return the list of available methods via the Allow header, as well as some as-yet-to-be-decided form of schema definition of what can be PUT or POSTed.
Rebel: A RE(ST API for X)BEL
· Thursday, January 17th, 2003 ·
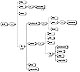
I have been building a REST interface for storing bookmarks marked up using the XBEL schema as a sort of counterpoint to Microsoft's Cold Rooster SOAP example. It quickly became obvious however that XBEL, being such a general hierarchical format of folders and bookmarks, could serve as the basis for organizing many types of data. The most immediate one that comes to mind, is allowing for better weblog categorization and production of RSS 2.0 feeds. See below.
I’m interested in getting feedback on the REST interface that I've outlined here. Any comments would be very welcomed.
Sections
The Rebel Interface
The interface is built around the three major elements of XBEL: <xbel>, <folder> and <bookmark>.
Folders are stored under URLs that end in “/”, and bookmarks are stored under URLs that do not end in “/”.
The <folder> Element
URL Format
xbel/.../folder-name/
Interface
| HTTP Method | Description |
|---|---|
| GET | Get the folder and it’s children. See below. |
| POST |
If a <folder> is POSTed, create a new folder under the given url. If a <bookmark>is POSTed, create a new bookmark resource under the given url. If any other entity type is POSTed, it is accepted and made a part of the resource, but no new resource is created. Note: For the current implementation, all <folder> and <bookmark> elements must contain an id attribute; this is used to produce the url of the new resource. See below. |
| PUT |
Create or update the folder at the given url. If the folder already exists, it will be replaced by the PUT entity; all children of the resource will be replaced by the children of the entity also. If the parent folder(s) do not exist, they will be created as necessary. Note: For the current implementation, the value of the id attribute must match the last element of the hierarchical URL name. See below. |
| DELETE | Delete the folder and all it’s children. |
| OPTIONS | Returns an Allow header, as well as metadata specifiying the schema of entities that can be PUT or POSTed. |
The <bookmark> Element
URL Format
xbel/.../folder-name/bookmark-name
Interface
| HTTP Method | Description |
|---|---|
| GET | Get the bookmark. |
| POST | Accepts the entity and includes it under the bookmark, but no resource is ever created. |
| PUT | Create or update a bookmark at the given url. If the parent folders
do not exist, they will be created also, as necessary. Note: For the current implementation, the value of the id attribute must match the last element of the hierarchical URL name. See below. |
| DELETE | Delete the bookmark and all it’s children. |
| OPTIONS | Returns an Allow header, as well as metadata specifiying the schema of entities that can be PUT or POSTed. |
The <xbel> Element
URL Format
xbel or xbel/
Interface
The <xbel> element is handled exactly the same way as the <folder> element, except that the <xbel> element can be referenced with or without the trailing “/”, other than that its behavior is the same.
The
<title>,
<desc>,
<info> and
<metadata>
Elements
Interface
All these elements are common to the folder, bookmark and XBEL document elements. They are semantically rich but they are not themselves addressable resources. Any of these elements can be POSTed to the XBEL element that they are describing, but they do not return a resource location.
The
<alias> and
<separator>
Elements
Interface
These elements are common to the folder and XBEL document elements. They are semantically rich but they are not themselves addressable resources. Any of these elements can be POSTed to the XBEL element that they will be included with, but they do not return a resource location.
It really doesn't make much sense to POST a <separator> element to it’s parent as it will simply be appended to the list of children. If seperators are need, the parent should be edited by the client and then PUT.
Open Issues
A note on ids
As discussed in the interface section above, this implementation currently requires the use of the “id” attribute which is defined as optional in the XBEL schema. While it would have been possible to use the title element to construct a URL, the results would often times would have been a grim looking URL, e.g., /The%20New%20York%20Times, as opposed to /nytimes.
I would be grateful for any ideas on how to deal with this situation. One idea that I had was to allow for both, but have a URL based on the title issue a 301 redirect to the id if one exists.
A note on hierarchy
Currently the API is defined as such that performing a GET on a folder returns the full tree that it parents. When I was thinking about this application strictly in terms of bookmarks that hardly seemed to be a terrible concern as the file wouldn’t as a general rule be particularly huge. If however the file began to contain verbose description contents as it could if it were supporting, say, the content of a weblog, this could quickly become unwieldy. While it wouldn't necessarily happen that often, having to GET then PUT a large block of bytes just to manipulate the content on a resource high up the hierarchy could be an issue.
I've decided the way to handle this is to expose a different resource-space for dealing with the XBEL information as a collection of “flat” resources. The url structure and API will be the same except for the /xbel “root” element. Instead the top level will be:
xbel-flat or xbel-flat/
And format will contain xlink references to it’s children, e.g.:
<folder id="standards" xmlns:xlink="http://www.w3.org/1999/xlink">
<title>Standards Documents</title>
<info>
<metadata owner="Jeffrey Winter">
</info>
<description>A collection of information about standards</description>
<bookmark xlink:href="servlet"/>
<folder xlink:href="rfcs"/>
<folder xlink:href="w3c"/>
<bookmark xlink:href="xbel"/>
<separator/>
<bookmark xlink:href="rss"/>
</xbel>
A note on exports
Currently this API deals with fragments of XBEL documents; when an entity is requested via GET it returns just the element requested, which except for the case of the root <xbel> element is not strictly a conformant XBEL document, i.e., it would not validate against the XBEL DTD.
To deal with this issue, there will be another resource-space that returns strictly XBEL conformant XML documents. This will be a read-only (i.e., GET-only) interface for possibly sharing folders. The url structure will be the same except for the /xbel “root” element. Instead the top level will be:
xbel-export or xbel-export/
Implementation
This current implementation is written for a Servlet 2.3 servlet engine (such as Tomcat 4.x.) It uses Xerces and Xalan for XML manipulation. For client-side testing, I use cURL.
This implementation is also written such that it manipulates and stores the document as a single XML document. This is clearly less than optimal but it works well as a simple way to work with the REST interface to help clarify it from a design perspective. I’ve isolated most of the XML machinery so that a version that works with a directory structure or a database should be a relatively straight-forward implementation of a base interface. My plan is to work on that refactoring after hearing any feedback, etc.
XBEL vs. RSS?
It struct me after looking at the
RSS 2.0 format, that XBEL
could easily be used for managing weblog content—with the <bookmark>
element corresponding to the RSS <item> element. The XBEL could
easily be transformed into RSS, and might offer a better way of storing, organizing
and categorized a weblog and its feeds because of its hierarchical schema.
The basic idea is that you POST directly to a specific category, or PUT to an item in a specific category for the content. It makes more sense to POST an entry to:
http://www.xefer.com/xbel/code/java/
or PUT an entry to:
http://www.xefer.com/xbel/code/java/javastory
With the <alias> element, these items can be referenced in
numerous ways; for example, there could be a daily feed at the folder
http://www.xefer.com/xbel/current
POST an <alias> element that references a new item that had
been stored under a specific category in context. The daily RSS feed would be a
<folder> with just a list of <alias> s.
When it’s time to archieve a month’s worth of items, obtain the current folder, PUT it to a folder /xbel/2003/01, remove the contents of the current folder and PUT it back to /xbel/current.
To actually support the RSS feed itself, a different root folder (handled by a different servlet for example) would be employeed that dereferenced the XBEL feed and performed a transformation on the response. So there would be two corresponding URL bases:
http://www.xefer.com/xbel/
http://www.xefer.com/rss/
Of course, the same idea could be used to produce other types of content, HTML or whatever.
This seems a better way to organize data than having an entry with, say, a <category>code/java<category> element imbedded somewhere within it and POSTing it to:
http://www.xefer.com/xbel
RSS 2.0 does have a <category> element, but
it is tucked into the <item> element in a way that
models a URL’s hierarchical format but without actually exposing it.
RSS 2.0 does of course allow multiple <category> elements,
and this is perhaps one issue with the XBEL approach: With XBEL, the categories
themselves would have to reference the elements they don't directly own
with <alias> elements. Essentially, both RSS 2.0 and XFML
provide a child→parent relationship from the item to the category; XBEL being
purely hierarchical has only a parent→child relationship expressed explicitly
through containment. Any other relationships require the an <alias> element.